The test failed. You read the output, decide it has nothing to do with your change, click rerun, and wait. It passes. You merge. Nothing was fixed. Nothing was even diagnosed.
That is the rerun trap, and it is how flaky tests propagate. How to fix flaky tests starts with naming which kind of flake it is. Almost every flake worth fixing falls into one of six root-cause classes: timing and async race conditions, test order dependency and state bleed, external resource flakiness, resource contention under parallelism, non-deterministic data and unseeded randomness, and environment-dependent assumptions. Each class leaves a different signature in the failure output. Once the class is identified, the fix narrows from “make it stop failing” to one of a handful of well-known patterns.
What follows is the diagnostic sequence in the order it should actually be run, the six classes with their telltale signatures and fixes, and the upstream question most teams skip. When external-resource flakes and parallel-contention flakes keep returning, the test isn't the problem. The test strategy is. Contract tests plus in-memory fakes are the structural fix most “how to fix flaky tests” content misses. The cost case for fixing rather than rerunning lives in the cost of flaky tests. The broader stability framing, including the healthy/flaky/broken classification model and the detection mechanics, lives in the complete guide to pipeline stability.
How to fix flaky tests: first, read the failure output
Before guessing a class, read the failure. The shape of the error message is the cheapest signal in the diagnostic toolkit, and most flakes give themselves away in the first ten lines of output. A test runner's log is the only file with the truth of what actually happened, so the first habit is to skim it before doing anything else.
Three rough buckets cover the majority of failure outputs. Assertion mismatches (“expected X but got Y”) lean toward state bleed, order dependency, or non-deterministic data. Connection or I/O failures (“ECONNREFUSED”, “ENOENT”, “DNS lookup failed”) lean toward external resource flakiness, resource contention, or environment. Timeouts (“Timeout after 30000ms”, “test exceeded deadline”) lean toward timing races or resource contention under load. None of that is deterministic; an assertion mismatch can be a race condition and a timeout can be a runaway test. But the bucket narrows the search space, which is the point of the first pass.
Classify before fixing
Six root-cause classes cover almost every flake worth fixing. Naming the class is the difference between a one-line fix and a week of guessing.
- Timing and async race conditions. The test assumed an operation finished by the next line, or gave up before the system caught up.
- Test order dependency and state bleed. State left behind by one test affects another, either through ordering or through a race between tests and their teardown.
- External resource flakiness. Network, DNS, or a third-party API misbehaves and the test implicates the system under test instead of the dependency.
- Resource contention under parallelism. Parallel workers fight for the same port, file, or database row.
- Non-deterministic data and unseeded randomness. RNG without a seed, time-based assertions, or unordered collections compared as if ordered.
- Environment-dependent assumptions. The test passes on a developer laptop and fails on CI (or vice versa) because the runtime environment differs: locale, OS, paths, time zone.
The diagnostic questions are short. Does the test fail in isolation, in a specific order, randomly regardless of order, only on CI, only under parallelism, or only on the second Wednesday of the month? The answer collapses the search.
Timing and async race conditions
Timing flakes come from code that assumes an operation is complete because enough wall-clock time has passed. setTimeout followed by an assertion, fixed sleeps in test setup, hard-coded timeouts on async polling, polling intervals that race with the system under test. The pattern is the same: the test reads state that has not yet settled.
Telltale log signatures: “Timeout after Nms”, “Maximum poll interval exceeded”, or an assertion reading the right shape of data but with a stale value (the wait returned before the system caught up).
The fix is to replace time with a condition. Polling on a predicate (“wait until the queue is empty”, “wait until the row appears”) with a generous upper bound is the standard pattern in Playwright, Cypress, Testing Library, RSpec, and most modern test frameworks. Where polling is not available, raise the timeout deliberately rather than incrementally; small bumps tell the next engineer the symptom was treated, not the cause.
Test order dependency and state bleed
These two are related but distinct. Order dependency means the test passes alone and fails inside the full suite, or passes on one CI shard and fails on another because the suite's ordering changed. State bleed means the test fails intermittently even with a fixed order, because the bleed happens between a parallel worker that produced the bad state and the worker that read it.
The diagnostic question is which one applies. Run the suite in random order on the local machine. Test runners offer this directly: pytest-randomly, jest with --testSequencer, RSpec with --order rand, Go with -shuffle. If the failure reproduces and the seed is captured, the cause is order dependency: bisect to the offending pair and decouple. If random-order runs are clean but parallel runs still fail, the cause is state bleed: the polluter and victim share mutable state, and the race is real concurrency rather than ordering.
The fixes diverge. Order dependency is fixed by making the failing test set up its own state, by making the polluter teardown what it created, or by switching to per-test fixtures. State bleed needs hermetic fixtures full stop: transactional rollback for databases, fresh containers per worker, a reset hook for singletons, snapshot-and-restore for environment variables. Cleaning is fragile (the polluter has to remember to clean correctly forever); hermetic fixtures are a one-time cost that pays back on every subsequent test.
External resource flakiness
External resource flakes happen when a test calls a real external component (a network service, DNS resolver, third-party API, message broker) and that component misbehaves. The test reports failure, and the failure implicates the system under test even though nothing the team owns is broken.
Telltale log signatures: “ECONNREFUSED”, “DNS lookup failed”, third-party 5xx responses, certificate errors, “upstream connect timeout”, broker reconnect lines. Tests that reach across a network boundary tend to cluster these failures by provider rather than by test, which is the second clue: when the same three providers account for nine out of ten flakes, the cause is upstream.
The tactical fix is to remove the external call from the test. Mock at the boundary, replay a recorded response, or substitute an in-memory fake. The deeper fix is a test strategy that does not depend on the external component to begin with; that is the section below on test strategy.
Resource contention under parallelism
Contention flakes happen when parallel test workers fight for the same resource. The shape is intermittent failure that correlates with worker count: at one worker the suite is clean, at four workers a handful of tests fail non-deterministically, at eight workers half the suite is red.
Telltale log signatures: “address in use” on a fixed port, “database is locked” from SQLite, “duplicate key value violates unique constraint” from a shared sequence, file-not-found on a path the previous worker already deleted. The signature usually names the contended resource directly in the error.
The fix is to give each worker its own copy of the resource. For ports: bind to port zero and let the OS allocate, then read the port back. For databases: a database per worker (testcontainers, ephemeral postgres), or a schema per worker on a shared instance. For files: a unique temp directory per worker. For shared sequences: scope the sequence to the worker. Where worker-scoped resources are impractical, serialise the affected tests instead of parallelising them; the runtime cost is usually trivial compared to the cost of permanent flake.
Non-deterministic data and unseeded randomness
Tests that read the system clock without freezing it, tests that use random values without seeding the RNG, tests that iterate an unordered collection in iteration order and assert on the order; each one introduces a source of variation the test author did not intend.
Telltale log signatures: an assertion failure where the shape of the data is right but the order is wrong (set or hash-map ordering); time-comparing assertions that fail when the test crosses a second boundary; randomly-generated test data that happens to collide with a fixture. Stack traces usually point straight at the comparison; the source of non-determinism is the upstream value.
The fix is to remove the variation. Seed the RNG explicitly with a known value (every test framework supports this directly or through a library). Freeze time around assertions that touch it (libfaketime, freezegun, sinon fake timers, Java's Clock). Sort or normalise collections before comparing. Where randomness is the point (property-based testing, fuzz), log the seed in the failure output so the run is replayable.
Environment-dependent assumptions
Environment flakes pass on a developer laptop and fail on CI, or pass on one runner image and fail on another. The cause is something about the runtime environment that differs between the two and that the test silently relies on: a locale, an OS family, a path separator, a time zone, an installed system library, a font, the user the runner runs as.
Telltale log signatures: locale errors mid-string ( “invalid byte sequence”), time zone offsets that look an hour off after DST changes, “no such file” on a path that uses / when the runner is Windows, certificate trust errors that validate locally and fail in the runner, font fallback differences in screenshot tests.
The fix order is replicate, then assume nothing, then constrain the environment. Replicate the runtime locally with Docker, matching the CI runner image, and reproduce the failure. Where reproduction works, fix the assumption: use path.join rather than literal separators, set a canonical locale and time zone in test setup, pin the system libraries the test depends on. Where replication is too expensive, pin the runner image so the environment at least stops drifting.
Step back: is the test strategy creating the flakes?
Classes three and four (external resource flakiness, resource contention under parallelism) tend to recur on the same teams for the same reason: the test suite is dominated by tests that call real external components. Terminology varies (integration tests, end-to-end tests, connected tests, broad-stack tests), and which boundary counts as “external” depends on the writer. The pattern is the same: a test that depends on a real component the team does not fully control becomes a flake vector the moment that component blinks.
Many test suites grow this shape by accident. A unit test that should have been a unit test reaches across a service boundary because the service was already running on localhost during development. The convenience stays in once CI starts running it. Over time the suite is dominated by tests that depend on real services, databases, file systems, and the network, and every dependency is a flake vector that compounds with worker count.
The structural fix is to push these tests down. For each integration boundary, ship two things: a contract test that exercises the real dependency and proves the boundary still works, and an in-memory fake that other tests use in place of the real dependency. The contract test runs slowly and rarely (nightly, or on a tag) and catches drift. The fakes run fast and deterministically and get used by every unit and use-case test that no longer needs to call the network at all. Both implementations pass the same contract test, so the fake stays honest as the real dependency evolves.
The cost is the work to write the contract tests and fakes once. The saving is the per-test flake tax that compounds with every new boundary-crossing test. A suite scales with how few real-dependency tests it has, not how many. If external resource flakes and parallel contention flakes keep coming back to the same triage queue, the test isn't the problem. The test strategy is.
Why “just rerun” is not the fix
Rerun-on-failure as policy is the anti-pattern that produces permanent flakes. Every rerun pays compute the provider billed and wait time the team paid, twice. Every rerun also strips a layer of confidence from the suite as a signal, because the suite's job is to say whether the change is safe, and a suite that needs to be re-run is a suite the team has stopped trusting.
A single rerun to confirm a suspected fix is fine. A rerun button wired up to merge on second pass is not. The cost shape of the second behaviour is laid out in the real cost of flaky tests: compute doubled per flake, wait time doubled per flake, and a compounding curve as engineers learn that rerun is policy rather than diagnostic.
When to quarantine instead of fix
Some flakes are not worth fixing this week. The owning team has moved on, the code path is being retired, or the flake rate is already low enough that the fix is more expensive than the noise. Quarantining is the right call in those cases, but only if the quarantine is visible.
Visible quarantine means three things. The skip is annotated with an owner and a reason, in whatever the framework offers:
- JUnit 5:
@Disabled("flaky on CI, see #1234") - Jest / Vitest:
it.skip("flaky on CI, see #1234", ...) - xUnit (.NET):
[Fact(Skip = "flaky on CI, see #1234")] - pytest:
@pytest.mark.skip(reason="flaky on CI, see #1234")
The pattern is the same across frameworks: skip plus reason plus ticket reference, never just skip. A ticket exists in the team's register with the intended unquarantine date. A metric tracks the number of quarantined tests over time. Silent quarantine, where a test is skipped and forgotten, becomes permanent skip, which becomes dead code in the suite. The cost is paid once when the team writes the next regression and the missing coverage bites.
How CI/CD Watch surfaces which tests are flaky
CI/CD Watch, a CI/CD observability platform that monitors pipelines across GitHub Actions, GitLab CI, Bitbucket Pipelines, CircleCI, Azure DevOps, and Jenkins, treats flaky tests as a first-class signal. JUnit reports from the providers are parsed on ingest, individual tests are tracked across runs, and the classification (healthy, flaky, broken) is computed per test and per workflow. The diagnostic work above still has to happen; what the platform does is name the tests worth diagnosing first.
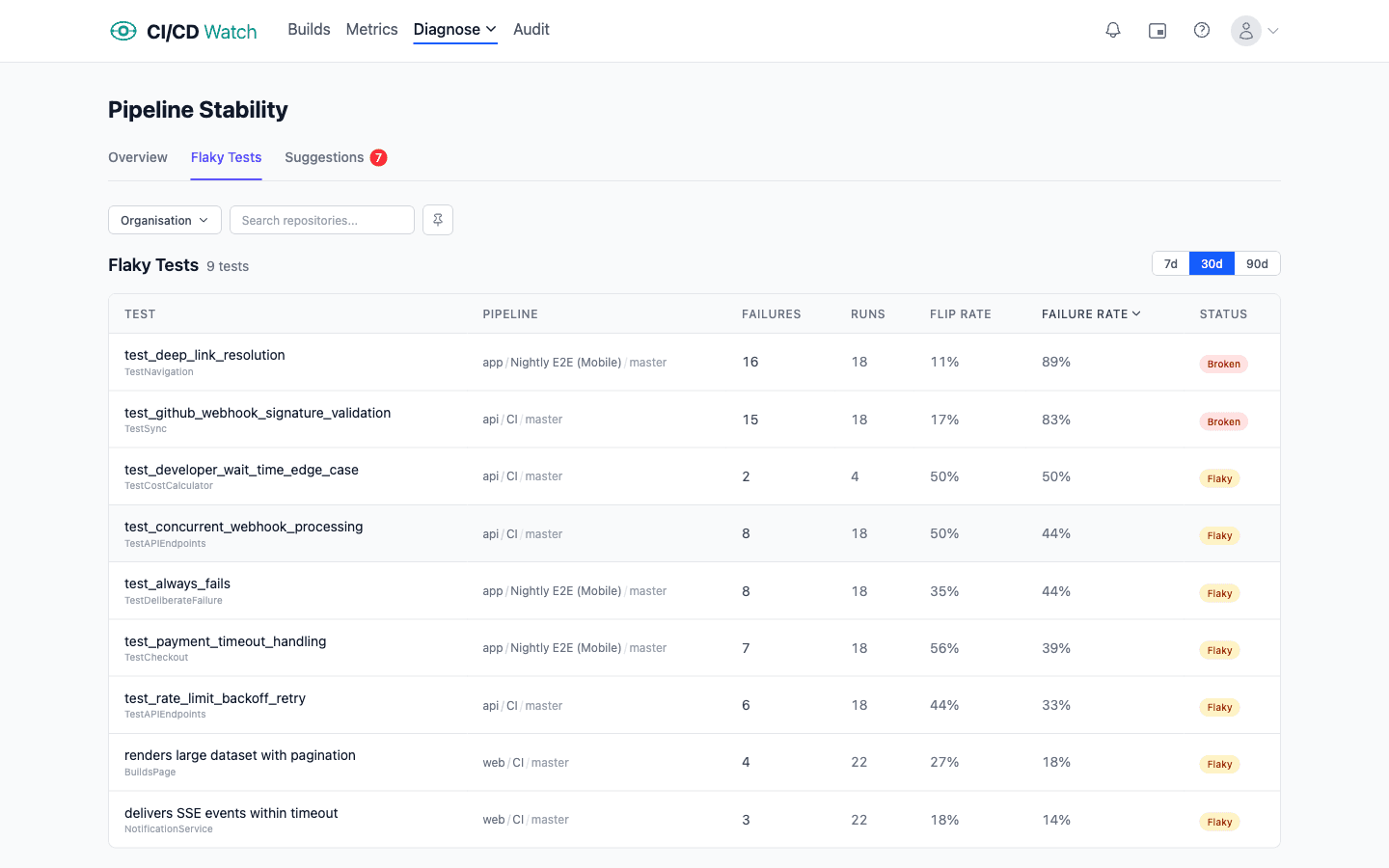
At the workflow level, the same classification rolls up: each workflow gets a healthy / flaky / broken label based on the aggregated test signal and the rerun pattern across recent runs. Spotting where flake clusters lives at this layer; the per-test view above is for triaging a specific row.
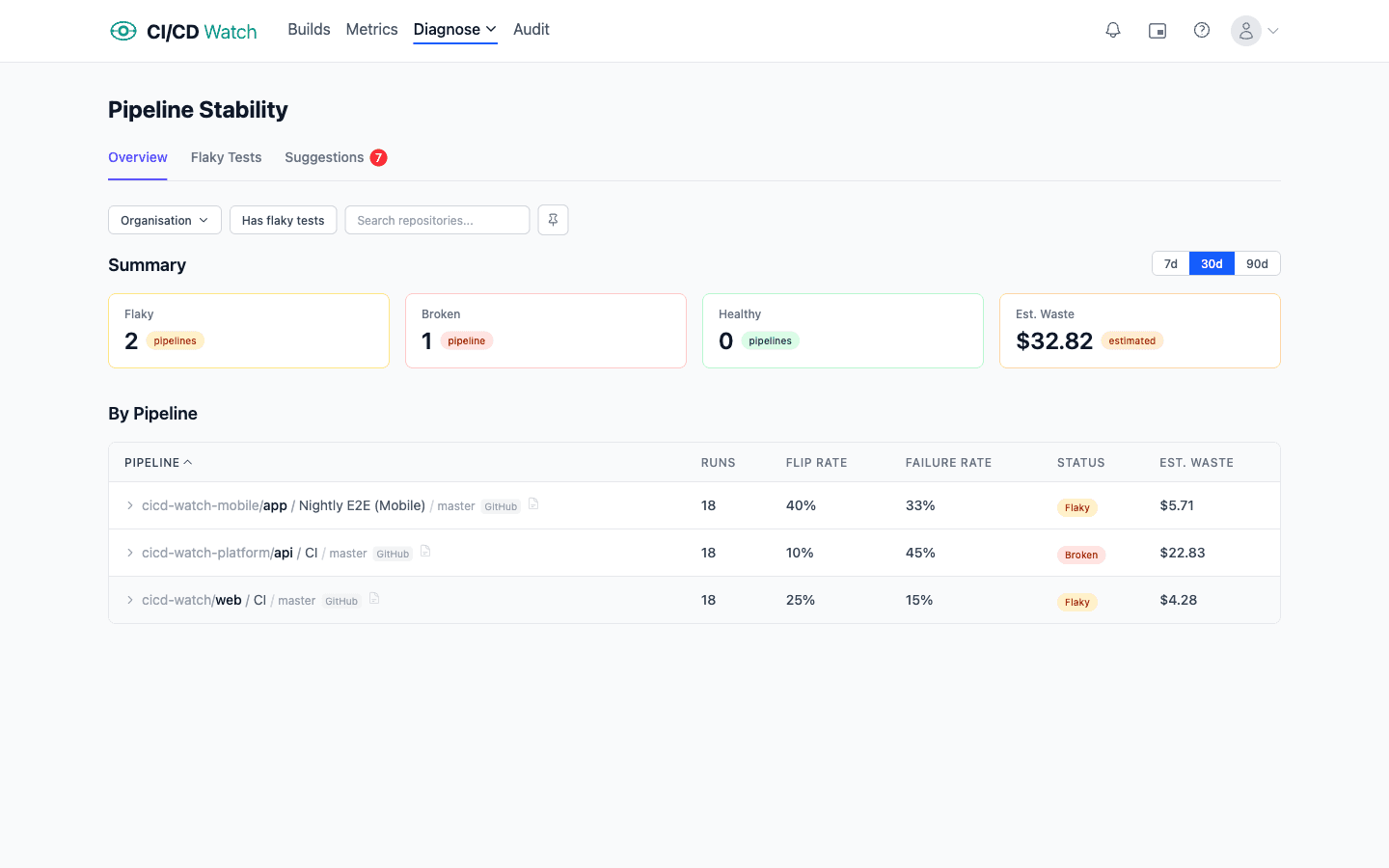
Per-test flip-rate scoring, the healthy/flaky/broken classification, and the rerun-rate signal that distinguishes rerun-as-policy from rerun-as-diagnostic live on the Team plan and above. The Free tier covers pipeline-run monitoring across connected providers, which is enough to see when reruns are happening before deciding whether the per-test detail is worth digging into.
Stop running tests that keep coming back to bite you
CI/CD Watch's Free tier covers pipeline-run monitoring for small teams. Connect a provider and see the rerun pattern across your CI estate, the entry point to the broader pipeline stability picture. Per-test flip rate, the healthy/flaky/broken classification, and the cost view that ties rerun rate to wait-time spend live on the Team plan and above.
CI/CD Watch is built by 3CS Technologies Ltd. It started as an internal tool for tracking pipeline health across a mixed GitHub Actions and Jenkins estate. The same engine now powers the SaaS platform.