Two engineering managers from the same company compare notes on lead time. One reports a median of three days. The other reports six hours. Same teams, same deploys, same calendar. They are measuring different intervals on the same activity, and neither of them realises it.
Lead time for changes is the most defensible DORA metric on paper and the easiest one to disagree on in practice. The metric's definition is short: time from a code change being made to that change running in production. The disagreement lives in three words. Code change being made can mean the first commit the developer authors (wherever it lands), the merge to main, the moment a pull request opens, or the moment review approval lands. Pick a different starting point and your lead time number can change by an order of magnitude without any team behaviour actually shifting.
That clock-start decision sits inside the broader DORA metrics framework: the four throughput-and-stability metrics (deployment frequency, change lead time, change fail rate, failed deployment recovery time) plus deployment rework rate, added in the 2024 DORA Report. What follows is the lead-time half of the throughput pair: what the metric actually measures, where to start the clock, and what to do when the number is too high. The deployment frequency half lives separately.
What lead time for changes actually measures
The DORA definition, since the 2018 Accelerate research and reaffirmed in every annual State of DevOps Report since, is the time it takes for a code change to get from authored to running in production. The metric targets the question: how long, end to end, between a developer making a change and that change reaching users?
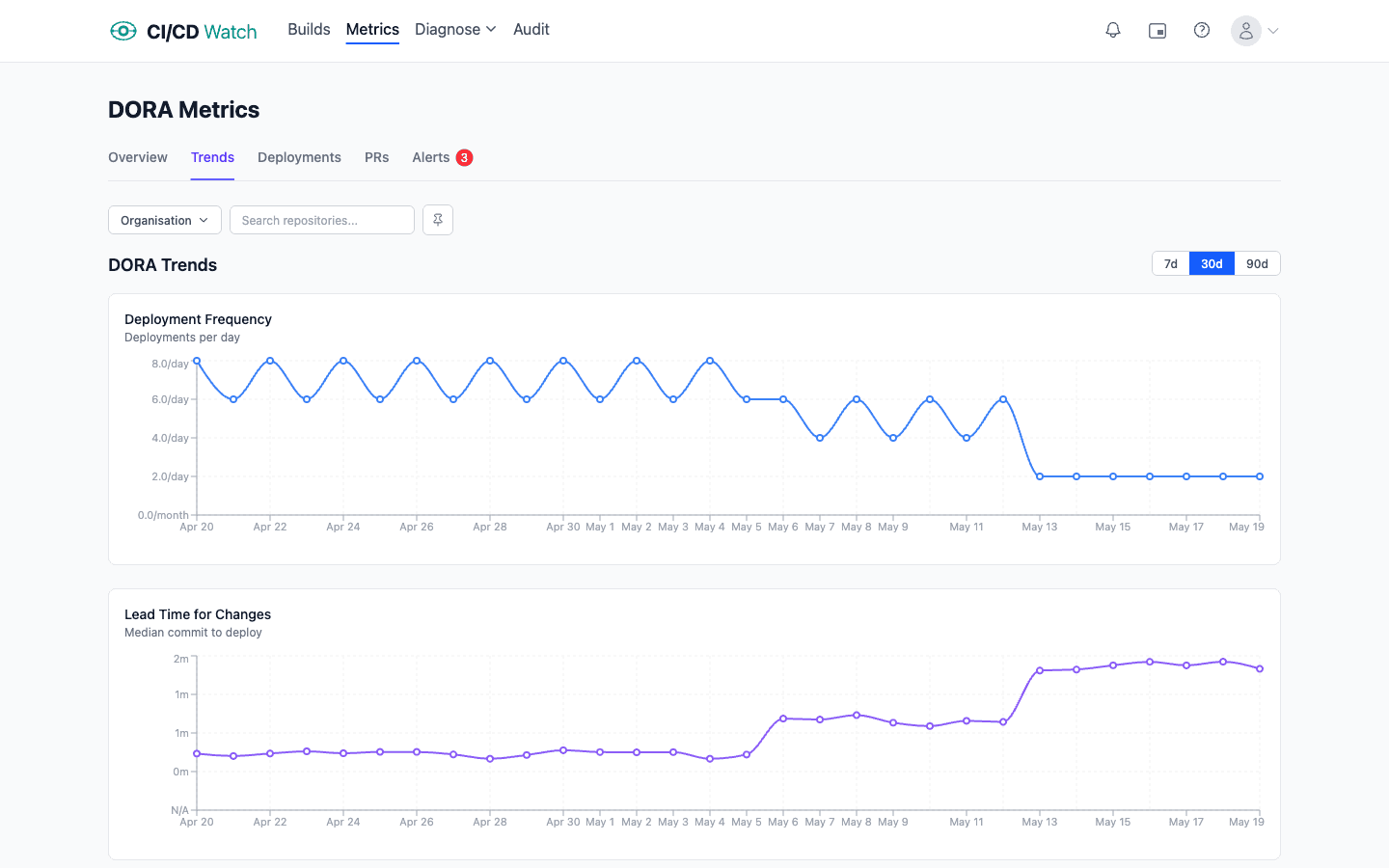
The 2024 DORA Report's thresholds for the four performance bands sit at well-known intervals: under one day for Elite teams, between one day and one week for High, between one week and one month for Medium, and over one month for Low. The bands sit far enough apart that within-band variance does not matter: a team that lands at five days versus three days is not meaningfully different in DORA terms, but a team at three weeks versus three days absolutely is.
What the bands measure is not raw engineering speed. They measure whether the path from commit to production is set up to be short. Small batches, fast CI, social programming (pairing or mobbing) so review happens as code is written, trunk-based development. Lead time is the diagnostic thermometer for those practices, not a target for an engineer to optimise on their own.
Where to start the clock: first commit, merge, or PR?
The clock-start choice is the one that determines whether two managers comparing notes are measuring the same thing. Three candidate start points appear in the wild, with very different properties. Take a position; do not let each team pick its own.
First commit. The strictly correct answer per the DORA definition, and the position we take. The clock starts when the developer authors the first commit of the change (directly on trunk for a small change, or on a short-lived branch), even if it sits unpushed for a day. This is the most informative number because it captures everything: local iteration, push timing, review queue, CI, deploy. Crucially, every minute the change spends in someone's editor or in review counts the same as a minute on a runner; that is the whole point of measuring lead time end-to-end.
Merge to main. The compromise most teams settle on. The clock starts when the change lands on the trunk and stops when it deploys to production. It is unambiguous in Git history and stable across teams. It is also a number that rewards teams who hide their slow phases. A change that sits in review for a week and merges in a minute looks identical to a change that gets reviewed in an hour and waited six days for a merge window. Both report the same fast lead time, and the difference, the part the team can actually fix, is invisible. Measuring from merge-to-main gives you a CI duration metric with a DORA label on it.
PR creation. The wrong answer, even though some product dashboards default to it. PR creation is gameable: a developer can delay opening a PR until the change is review-ready, then report fast lead times because the slow pre-PR phase has been hidden. It also penalises teams who do the right thing by opening early-draft PRs to discuss approach. The metric becomes a measure of when the team chooses to announce work, not when work happened.
First commit is the only clock-start that resists this kind of hiding. The common objection is that it is hard to measure: local clocks drift, people squash-rewrite history, draft commits are sometimes amended away. Those are real but solvable. Use the earliest committer timestamp from the change's commits (on the short- lived branch if there is one, otherwise the run of trunk commits that ship together), fall back to the first push to a remote when local timestamps are missing or implausibly skewed, and treat squash-merges by reading the commits from the source branch before they were rewritten. The numbers will be slightly noisier than a merge-to-main query, and they will tell you the truth about how long changes actually take.
Why "deployment" is the other ambiguity
The clock-stop is the second source of disagreement. Lead time stops when the change reaches production. What counts as production?
A successful build that runs tests is not a deployment. A deploy to a staging environment is not a deployment in DORA terms either. A deploy to a customer-facing environment is the right answer, but on most estates that requires defining which workflows actually deploy and which only build, test, or promote artefacts. The cleanest approach is to declare a deployment rule per service: a tag push to main, a manual promotion through a gate, a successful run of a specific workflow named in a config file. Pick the rule, document it, apply it uniformly. A different rule per team makes cross-team comparison meaningless.
The detail of which signals fire which deployment definitions is treated end-to-end in how to measure DORA metrics: the practical decisions you have to settle before any DORA query gives you a number you can defend.
What drives lead time up
Once the definitions are settled, a high lead-time number usually decomposes into three contributors. They show up in different proportions on different teams, but the diagnostic order is the same.
Batch size. The single biggest driver. A change that touches fifteen files and sits in review for three days because reviewers need an hour to read it is paying batch-size cost. Smaller batches review faster, ship faster, and fail faster when they fail. The fix is upstream of CI: trunk- based development with feature flags decoupling deploy from release.
Review queue time. If the merge-to-main number is fast but the first-commit-to-merge interval is slow, the queue is the problem. Waiting on a single named reviewer, unclear review ownership, or a CAB that meets weekly all show up here. The cleanest fix is social programming (pairing or mobbing) so review happens in real time as the code is written, with pipeline automation catching regressions behind it. If not pairing, async approval by any qualified reviewer is the next-best option. The anti-pattern is the named-reviewer queue.
CI duration and instability. If the merge-to-deploy interval itself is the bottleneck, CI is the cause. Long pipelines and flaky tests compound here: a 20-minute pipeline that needs a rerun adds 20 minutes to lead time on every flake. The fix is practices-first (test ownership, quarantine policies) before tooling (parallelisation, caching). Throwing runner concurrency at a flaky pipeline buys speed without fixing the cause.
How to reduce lead time without breaking things
Reducing lead time is not the same as moving faster recklessly. The 2024 DORA Report data continues to show that throughput and stability move together: teams that improve lead time without compromising change fail rate are the ones that adopt the practices DORA has tracked since 2018. The order matters.
- Shrink the batch before optimising the pipeline. A 30-minute change in a small batch ships faster than a 5-minute change in a large batch, because the small batch never enters the slow review path.
- Pair or mob, with async review as the next-best option. Social programming collapses review into the writing itself, with pipeline automation behind it. If not pairing, define which group reviews which code and let any qualified person approve. Avoid naming a single reviewer per PR.
- Trunk-based development. Long-lived feature branches add integration risk and lead time. Merge to main daily, keep features behind flags.
- Fix flaky tests before adding parallelism. Parallelising a flaky pipeline gives you faster failures, not faster successes. Quarantine first, parallelise second.
- Decouple deploy from release. Feature flags let a change ship to production minutes after merge without being visible to users. Lead time falls; the user-facing release schedule stays under product control.
How CI/CD Watch surfaces change lead time
CI/CD Watch, a CI/CD observability platform that monitors pipelines across GitHub Actions, GitLab CI, Bitbucket Pipelines, CircleCI, Azure DevOps, and Jenkins, calculates lead time on every connected workflow that resolves to a deployment. The clock-start rule defaults to first commit, on the basis that hiding the pre-merge phase is the failure mode the metric exists to prevent. Merge-to-main and PR-open are available as configurable alternatives where a team has a specific reason to use them. The clock-stop is set per service through a deployment rule that names the workflow and the environment. How those rules are evaluated, including the chained-workflow case, is documented in the DORA metrics reference.
Lead-time trends and the Elite / High / Medium / Low band each repository falls into sit on the Team plan and above. The Free tier covers pipeline-run monitoring, which is enough to confirm the upstream signals (run volume, average duration, deployment cadence) are coherent before layering DORA analysis on top.
See your lead time across providers
CI/CD Watch's Free tier covers pipeline-run monitoring for small teams. Connect a provider to see deployment cadence and average duration across your workflows, the upstream signals the lead-time calculation depends on. Lead-time trends and the Elite / High / Medium / Low banding live on the Team plan and above. For the broader framework that lead time sits inside, the DORA metrics overview covers all five.
CI/CD Watch is built by 3CS Technologies Ltd. It started as an internal tool for tracking pipeline health across a mixed GitHub Actions and Jenkins estate. The same engine now powers the SaaS platform.