A test that has been green all week fails on a CI run. The engineer who pushed the commit reads the output, decides nothing they touched could break that test, and clicks rerun. Sixteen minutes later the pipeline is green. They merge.
Nothing was broken. Nothing was fixed. The cost of flaky tests starts here: two pipeline runs in the ledger for one commit's worth of progress. Repeat that across a quarter and you have the most expensive bug class your CI estate quietly carries — a failure mode nobody triages because every individual instance looks too small to bother with.
The cost of flaky tests is the story to tell first. Every rerun pays compute the provider billed and wait time the team paid, twice. Most teams account for the first, ignore the second, and quarantine neither, which is why flakiness compounds rather than burns off.
That cost framing sits inside the broader true cost of CI/CD: compute and developer wait time are the two components of pipeline spend, and wait time usually dominates by an order of magnitude or more. Flakiness is the cleanest example of why. What follows is the cost-angle treatment: the rerun maths, the compounding curve, what we have seen across customer workloads, and where the practices fix actually starts. The stability angle on the same problem (root causes, classification, detection mechanics) lives in the complete guide to flaky tests.
Why flaky tests are a cost driver, not noise
The dominant culture around flakiness is filtration. Reruns are treated as a tax on the pipeline, paid every time a test fails for reasons unrelated to the change being tested. The team accepts the tax, builds rerun automation around it, and moves on. The line of thinking is that flakes are noise, and noise gets filtered.
That framing is wrong on the cost ledger. A rerun is not a filter; it is a second full pipeline. Every minute of compute the provider billed for the first run gets billed again. Every minute of wait time the team paid gets paid again. A 5% rerun rate is a 5% tax on the entire CI estate, applied to both sides of the bill simultaneously.
It is also wrong on the practices ledger. A rerun culture is signal that branching, test ownership, or test environment hygiene is weaker than it looks. The flake itself is the symptom; the willingness to keep clicking rerun is the underlying problem. Quarantining the worst offenders is cheaper on every axis (compute, wait, signal quality, team morale) than accepting a permanent rerun tax.
The rerun maths: why every flake pays twice
The cost of a single flake on a single pipeline run is straightforward. The pipeline ran twice. Compute doubled, wait time doubled, the metering on both sides paid the full second run. There is no rerun discount.
cost per flaky run = (compute per minute × pipeline duration) + (hourly rate × pipeline duration ÷ 60 × engineers blocked)
On a 20-minute pipeline at $0.008 per Linux minute, the compute side of one rerun is roughly $0.16. Cheap. The wait side, on a 100-engineer team at a fully-loaded $75 per hour with one engineer blocked on the run, is about $25. Per rerun. If five engineers are downstream of the change (waiting for the merge, blocked on a shared service, holding open PRs that depend on it), the wait side multiplies accordingly.
Scale that up. A workflow with a 5% rerun rate and a hundred runs per day is paying for five extra full pipelines every day. A workflow with a 15% rerun rate (a level we observe more often than teams expect) is paying for fifteen extra full pipelines every day, on both sides of the ledger.
The reason this hides is that the per-flake number is small and the per-team number is large. No single rerun is worth a meeting. The aggregated annual figure is large enough to be a line item on the CFO's deck.
What we observed on a real CI workload
On a CI workload over a recent 30-day window, the rerun rate was 3.6% across 165 terminal pipeline runs. Roughly one commit in twenty-eight needed to be kicked again. The team considered the workload healthy.
That same workload had a wait-to-compute ratio of 142 to 1 on the cost view: $7 in compute against $977 in developer wait time over the window. Annualised, that is $84 in compute and $11,900 in developer wait time on the baseline. The six flaky reruns themselves were short — averaging 3.4 minutes before the contract violation tripped — so the direct rerun overhead came in at about $0.16 in compute and $25 in wait time over the window, or $2 and $310 annualised. Small per workload; the multiplier is across team count, pipeline duration, and rerun rate, all of which can be much higher than this example.
Across the providers we monitor (GitHub Actions, GitLab CI, Bitbucket Pipelines, CircleCI, Azure DevOps, and Jenkins), the rerun signal varies by team, not provider. Provider-specific rerun mechanics matter at the API level (how reruns are attributed, whether matrix jobs rerun individually, how cancels are counted), but the cost-driving rate is a function of test hygiene, not of which CI service runs the workflow.
The hidden costs that do not show on the runs page
The two-pipeline maths undercounts. Several real costs sit around the rerun and rarely appear in any naive duration view.
- Diagnostic time. Before clicking rerun, the engineer reads the output and decides whether the failure is related to the change. Even three minutes of that across a hundred reruns a week is two engineering days a quarter, paid at developer rates.
- Context-switch cost. Returning to deep work after an interruption takes about twenty minutes. A flake that pulls an engineer out of their editor for ten minutes can easily cost thirty minutes of real productivity on either side of the break.
- Reviewer churn. A pull request that fails CI three times in two days because of a flake earns a different label in a reviewer's head than one that goes green first time. Reviewers postpone merges they distrust. The shipping date slips by days, not minutes.
- False-confidence cost. Some flakes are genuinely environmental. Some are tests that intermittently catch real bugs and get reflexively rerun until they stay green. The latter ships defects. That cost is paid downstream by support and customers, and it is nowhere on the CI invoice.
- Red-main contamination. A flake on main that nobody chases turns into a permanent yellow status. Subsequent failures are dismissed as “more flakiness” until something actually breaks. One hour of red main on a 100-engineer team at $75/hour is $7,500 of pure wait time, and flakes are a frequent way to get there.
None of these show up in a duration metric, and none of them appear on a provider invoice. They are all paid out of salaries and customer trust.
How flakiness compounds with team size and pipeline duration
The annual cost of flaky tests is the product of three numbers teams already track or could easily measure: rerun rate, pipeline duration, and team size. The number nobody asks for is the multiplier that emerges when all three move at once.
| Team size | Pipeline duration | Rerun rate | Annual wait cost from reruns |
|---|---|---|---|
| 10 engineers | 10 min | 5% | ~$4,700 |
| 20 engineers | 10 min | 5% | ~$9,400 |
| 50 engineers | 15 min | 10% | ~$70,000 |
| 100 engineers | 20 min | 5% | ~$93,750 |
| 100 engineers | 20 min | 15% | ~$281,000 |
| 300 engineers | 20 min | 10% | ~$562,500 |
Each row uses three commits per engineer per day, 250 working days, $75/hour fully loaded, and one engineer blocked per run. Real teams sharing a single trunk see higher numbers, because more than one engineer is usually blocked on any given rerun. The compute side of the same table runs at roughly one to two percent of these figures. The argument for fixing flakiness does not need the compute number to land; the wait number carries it on its own.
The fix: practices first, then quarantine, then tooling
Treating flakiness as a cost problem changes the order of operations. The cheapest interventions are practice changes; the next cheapest are policy changes; tooling comes last.
Practice changes that reduce flakiness without buying anything:
- Trunk-based development with small batches. Smaller changes mean smaller blast radius when a flake triggers. Failing pipeline runs are easier to attribute to either the change or the test.
- Test ownership. A flaky test should have an on-call owner who triages it within a defined SLA. Without ownership, every flake is somebody else's problem and the rerun tax accrues.
- Failing builds block merges. A team that lets red CI through to main accelerates the rerun culture. Once the bar is “rerun until green,” the flake rate climbs because nobody is paying the triage cost.
Policy changes that cost discipline rather than money:
- Quarantine the top offenders. Most flakiness lives in a small number of tests. Move the top five into a quarantine suite that runs but does not block, and assign a rota to fix one a week. The aggregate cost falls fast.
- Cap rerun-on-failure. Some teams add automatic rerun-on-failure to their pipelines. That hides the rerun rate as a cost and lets it grow undisturbed. A cap (one rerun, manual after that) keeps the signal visible.
Tooling compounds the gains once the practices and policies are in place: test selection by changed file, parallel test execution, retry-with-bisect to localise an offender, JUnit parsers that classify failures by error type. None of those replace the practice work, and all of them depend on it. A rerun-tolerant culture pointed at better rerun tooling just spends more efficiently on a problem it should not have.
Reruns share their underlying cost shape with oversized runners, dead pipelines, and red-main blocks. Fixing flakiness is one front in a wider argument about developer wait time: the largest cost most teams pay for CI/CD is the wait component, and reruns are the most direct multiplier on it.
How CI/CD Watch surfaces the cost of flaky tests
CI/CD Watch, a CI/CD observability platform that monitors pipelines across GitHub Actions, GitLab CI, Bitbucket Pipelines, CircleCI, Azure DevOps, and Jenkins, treats reruns as a first-class cost. The cost view splits compute and wait time per workflow, and the rerun share of each is broken out as its own waste category. How the rerun rate is computed (terminal runs only, retries attributed to the originating commit, cancellation handling per provider) lives in the cost-calculations reference.
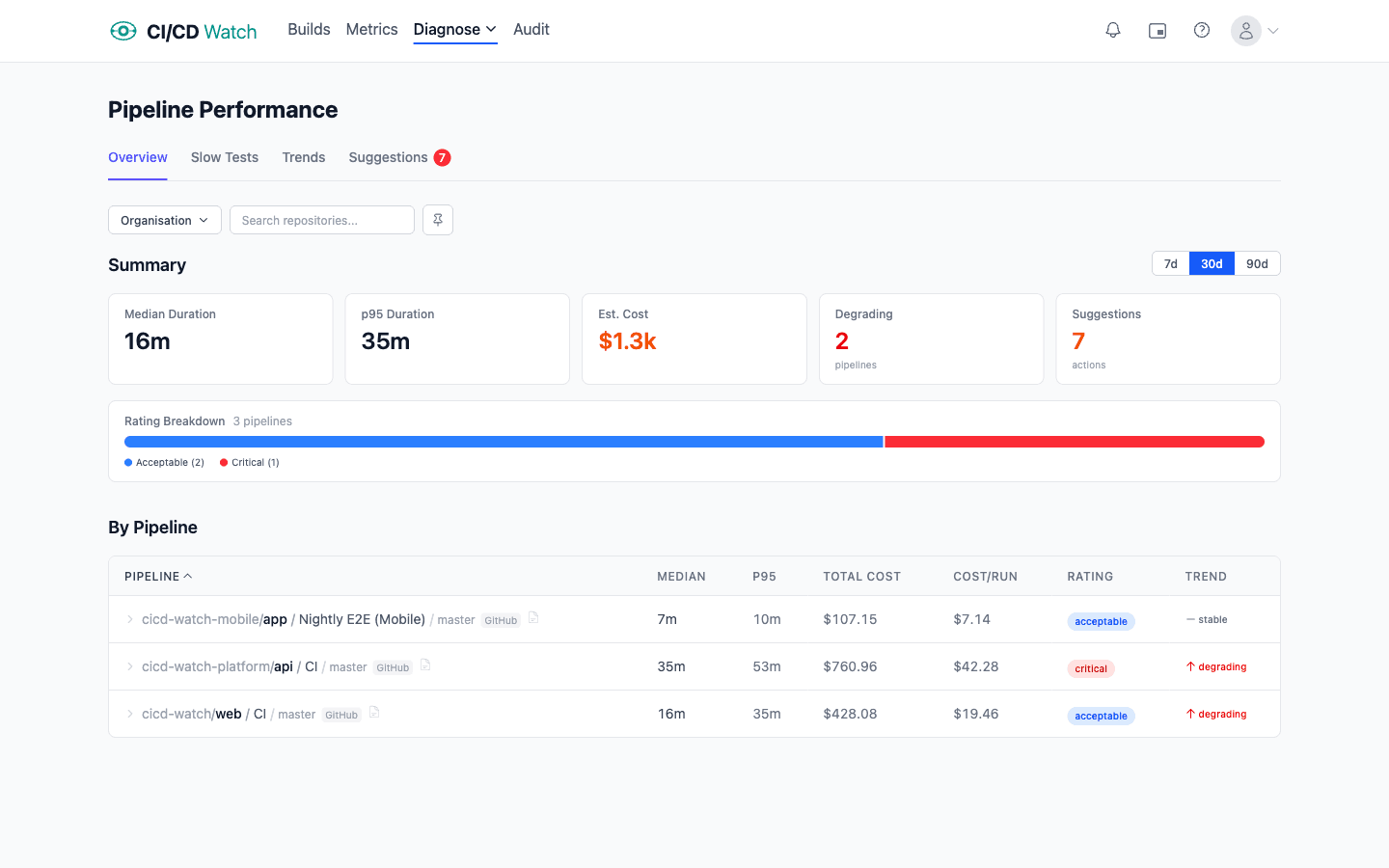
Stability detail (workflow-level rerun rate, flip-rate scoring, test-level classification across healthy / flaky / broken) and the cost view that splits compute against wait time live on the Team plan and above. The Free tier covers pipeline-run monitoring across your connected providers, which is enough to see the run volume and retry pattern flowing through your CI estate before deciding the cost picture is worth digging into.
See where flakiness is costing you
CI/CD Watch's Free tier covers pipeline-run monitoring for small teams. Connect a provider and see the run volume and retry pattern across your CI estate, the entry point to the broader true cost of CI/CD picture. Workflow rerun rate, flaky-test detail, and the compute-plus-wait-time cost view live on the Team plan and above.
CI/CD Watch is built by 3CS Technologies Ltd. It started as an internal tool for tracking pipeline health across a mixed GitHub Actions and Jenkins estate. The same engine now powers the SaaS platform.